- Client und Server
- Das Protokoll HTTP
- Die URL
- HTTP Request-Methoden
- HTTP Response
- Das HTTP-Paket
- Unterschiede zwischen HTTP/1.0 und 1.1
- Authentifizierung
- Web Caching
- Cookies
HTTP ist ein Protokoll der Anwenderschicht des TCP/IP und wird auf dieser Seite besprochen. Installation und Wartung des HTTP-Servers Apache wird auf einer anderen Seite behandelt.
HTML ist die Beschreibungssprache für die Hypertext-Dokumente.
Client und Server
- Als Client arbeitet ein Browser wie Firefox, Chromium oder andere.
- Als Server dient ein Rechner mit einem Web-Server wie Apache.
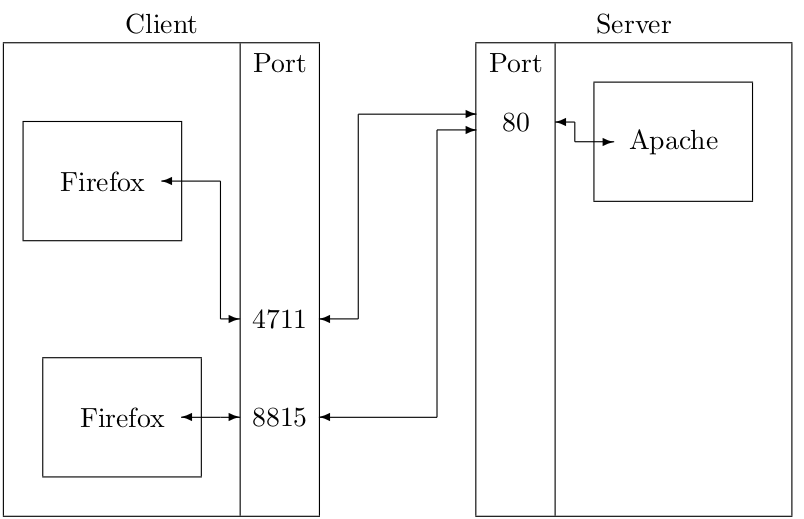
Der Standardport von HTTP ist 80. Die Übertragung erfolgt unverschlüsselt. Die aktuelle Version von HTTP/2 und ist in RFC 7540 definiert.
Als verschlüsselte Variante steht HTTPS zur Verfügung, die standardmäßig den Port 443 verwendet.
Das Protokoll HTTP
HTTP ist ein Protokall mit einer Client-Server-Struktur. Für einen tieferen Einblick können Sie einen Blick auf die Client-Server-Programmierung in C werfen.
- Der Client verwendet connect, um eine Verbindung zum Server zu erhalten.
Dabei verwendet er den well known port (80, 443) und die Adresse des
Servers. Er sendet eine Anfrage (send) und wartet blockierend auf die
Antwort des Servers (receive). Ist die Antwort eingetroffen, kann sich der
Client beenden oder er sendet eine völlig neue Anfrage.
- Der Server wird gestartet und versucht den well known port zu erhalten (bind). Über diesen führt er einen receive durch. Das blockiert den Server bis eine Anfrage eintrifft. Eine Anfrage wird den Server dazu veranlassen, die gewünschte Information zu beschaffen, beispielsweise in Form einer Datei, und diese per send an den Anfrager zu versenden. Anschließend begibt sich der Server wieder in den Empfangsmodus und wartet auf eine neue Anfrage.
Das Protokoll ist textbasiert. Das bedeutet, dass die Anfragen (Request) und Antworten (Response) im Klartext über die Leitung gehen.
Das Protokoll ist grundsätzlich statuslos. Das bedeutet, dass eine Sitzung nach der Antwort durch den Server endet. In seiner ursprünglichen Anwendung für den Austausch wissenschaftlicher Dokumente war das völlig ausreichend. Es vereinfacht die Kommunikation und sorgt für eine höhere Performance und Stabilität. In Zeiten von Online-Shops sind aber längere Sitzungen erforderlich. Das heißt, dass der Server mehrere Anfragen einem Client zuordnen können muss. Dies wird beispielsweise über Cookies realisiert.
Die URL
Eine URL besteht aus dem Hostname (oder dessen IP-Adresse) und durch einen Schrägstrich getrennt das gewünschte Dokument, das ggf. durch einen Pfad spezifiziert wird. Optional kann durch einen Doppelpunkt angehängt ein Port spezifiziert werden.
http://www.meinedomaene.de:80/hochschule/aktuelles/bild.jpg?anfrage=glas \____/ \_________________/\_/\___________________/ \______/\___________/ || || | || || || Protokoll Host Port Pfad Datei ParameterLeerzeichen und Sonderzeichen dürfen in der URL nicht auftreten. Werden sie in den Parametern dennoch benötigt, werden Leerzeichen beispielsweise durch %20 dargestellt. Andere Zeichen werden durch eine URL-Codierung umgesetzt, die von der Zeichencodierung abhängig ist.
HTTP Request-Methoden
Das HTTP-Protokoll kannte in der Version 1.0 die Befehle GET, HEAD und POST. Die Version 1.1 brachte noch PUT und DELETE hinzu.- GET: Hole eine Datei (Dokument) vom Server. Dabei übergibt GET eine URL.Die URL kann um Anfrageparameter ergänzt sein, die mit einem Fragezeichen abgetrennt, angehängt werden. Die meisten Anfragen dürften unter diese Kategorie fallen.
- POST: Sende Daten an den Server. Typischerweise sind dies Formular-Inhalte. Sie werden als Wertepaare aus der FORM eines HTML-Dokuments erstellt. Die Datenmenge ist weitgehend unbegrenzt und ist nur verschlüsselt, wenn als Protokoll HTTPS verwendet wird. Mit den übergebenen Daten können Server-Ressourcen angelegt oder verändert werden.
- HEAD: Holt nicht die komplette Datei, sondern nur den HEAD-Anteil.
- PUT dient vor allem zum Hochladen von Dateien. Die URL gibt das Ziel an. Ist unter der URL bereits eine Datei vorhanden, wird sie überschrieben.
- DELETE: Löschen einer Server-Ressource.
- CONNECT: Richte einen SSL-Tunnel ein.
Aufbau eines HTTP-Befehls
Eine Request beginnt mit der Zeile des Befehls. Beispielsweise lautet diese für einen GET der Datei index.htm folgendermaßen:GET /index.htm HTP/1.1Der Aufbau ist:
Befehl Leerzeichen URL Leerzeichen Version CR+LF
Alle Zeilen des Befehls werden mit CR-LF abgeschlossen.
Der Befehl GET besitzt nur einen HEAD, keinen BODY. Darum müssen eventuelle Parameter in der URL untergebracht werden. Das hat zur Konsequenz, dass diese Parameter nicht verschlüsselt werden können.
Der Head enthält allerdings durchaus weitere Informationen. Darin steht beispielsweise der Browser (User-Agent) oder die Sprache, die der Client bevorzugt (Accept-language). Durch einen Doppelpunkt getrennt werden die Inhalte übermittelt.
GET-Anfrage
Der Client sendet zunächst eine Befehlszeile mit dem folgenden Aufbau an den Server:- Das Schlüsselwort GET
- (optional) Der Pfad zur Datei
- (optional) Ein Fragezeichen, wenn Parameter folgen
- (optional) Parameterangaben, die untereinander durch & separiert sind:
- Variable
- Gleichheitszeichen
- Wert
- Protokollangabe mit Version, beispielsweise: HTTP/1.1
- Host: Adressat
- User-Agent: Mozilla etc, auch Plattform
- Accept: MIME-Formate, mehrere Angaben sind möglich.
- Accept-Language: Sprache
- Accept-Encoding: gzip
- Accept-Charset: ISO-8859-1 utf-8
- Keep-Alive: 300
POST-Anfrage
Eine POST-Anfrage folgt der gleichen Struktur wie eine GET-Anfrage. Allerdings sendet POST keine Parameter per URL. Die Parameter werden im Message Body (Payload) transportiert.- Auf diese Weise sind die Paramter in ihrem Umfang nicht beschränkt.
- Die Parameter werden im BODY transportiert. Dieser ist bei HTTPS verschlüsselt. Dagegen ist die URL nie verschlüsselt.
- Allerdings lassen sich auf POST-Anfragen keine Lesezeichen setzen. Bei GET-Anfragen funktioniert das.
HTTP Response
Die erste Zeile der Antwort des Server ist der Status-Code. Er folgt dem Aufbau:Protokoll Leerzeichen Nummer Leerzeichen Status CR+LFBeispielsweise ist eine positive Antwort:
HTTP/1.1 200 OK
HTTP-Status-Codes
Der Server antwortet auf Anfragen mit einem Status-Code in Form einer dreistelligen Zahl.| Basis | Zahlencode | Bedeutung |
|---|---|---|
| 1xx | Informativ | |
| 2xx | Erfolgreich | |
| 200 | OK | |
| 201 | Created | |
| 202 | Accepted | |
| 204 | No Content. Anfrage ok, aber kein neuer Inhalt | |
| 3xx | Es sind weitere Aktionen erforderlich | |
| 300 | Mehrere Auswahlmöglichkeiten | |
| 301 | Permanent auf anderer URL | |
| 302 | Temporär auf anderer URL | |
| 304 | Inhalt ist unverändert | |
| 4xx | Fehler des Client | |
| 400 | Fehlerhafte Anfrage, etwa ungültige URL | |
| 401 | Nicht authorisiert | |
| 403 | Verboten | |
| 404 | Nicht gefunden | |
| 5xx | Fehler des Servers | |
| 500 | Interner Serverfehler | |
| 501 | Nicht implementiert | |
| 502 | Falsches Gateway (Proxy-Anwendung) | |
| 503 | Server ist überlastet | |
| 505 | HTTP-Version nicht unterstützt |
Die Headerzeilen liefern zusätzliche Informationen wie Webserver (Server) und dessen Version.
Nach dem Header folgt der eigentliche Dateninhalt, die sogenannte Payload. Auf einen GET ist dies typischerweise ein HTML-Dokument.
Das HTTP-Paket
- Methode (GET, POST, etc)
- Leerzeichen
- Status-Code (beispielsweise URL)
- Leerzeichen
- Status-Inhalt (beispielsweise Version)
- Carriage Return und Line Feed (dez: 13 10)
- Header-Zeilen (mehrfach)
- Header-Feld-Name
- Doppelpunkt Leerzeichen
- Inhalt
- Carriage Return und Line Feed (dez: 13 10)
- Carriage Return und Line Feed (dez: 13 10)
- Daten
Unterschiede zwischen HTTP/1.0 und 1.1
HTTP/1.1 erlaubt mehr als 1 Objekt pro Anfrage und stellt damit den Übergang von non-persistent nach persistant dar.HTTP/1.1 ermöglicht Caching. Der Server meldet modified contents über ein ETag (Beispielsweise x234dff) und max-age (beispielsiweiese (max-age=120). Wendet sich der Client mit der gleicher ETag innerhalb der max-age, meldet sich der Server mit dem Status 304 ohne Payload.
Authentifizierung
Die Authentifizierung gehört bei einem statuslosen Dienst wie HTTP nicht zu den zentralen Elementen. Die Anmeldung für Webseiten ist in den meisten Fällen durch Web-Programmierung nachträglich aufgestülpt und wird nicht durch das Protokoll HTTP definiert.Allerdings können Sie ein Verzeichnis gegen unberechtigten Zutritt sperren, indem Sie dort eine Datei .htaccess hinterlegen. Damit können Sie eine Anmeldung des Benutzers erzwingen.
Wird eine Datei aus einem solchen Verzeichnis aufgerufen, erscheint eine Dialogbox, die Benutzername und Passwort erfragt und mit der in der .htaccess hinterlegten Passwortdatei abgleicht. Jene legt auch fest, auf welche Art (AuthType) kommuniziert wird.
- Basic: Das Passwort wird mit Base64 kodiert. Auch wenn ein mit Base64 kodiertes Passwort auf den ersten Blick krypisch aussieht, handelt es sich nicht um eine Verschlüsselung. Da heutzutage der Datentransport meist über HTTPS ist und damit verschlüsselt ist, bereitet das kein Problem.
- Digest: Das Passwort wird (im Allgemeinen mit MD5) per Hash verschlüsselt und kann entsprechend nicht einfach eingesehen werden. Da in der Passwortdatei das Passwort auch verschlüsselt vorliegt, kann eine Überprüfung durchgeführt werden, ohne dass das Passwort im Klartext über die Leitung geht.
Digest Access Authentication
RFC 2069, 2617, 7235
Ablauf
Der Browser hat eine Seite mit GET angefordert, die in der Datei .htaccess durch eine Digest Authorisation geschützt ist. Darin liegt das durch die Hashfunktion md5 verschlüsselte Passwort und der Benutzer im Klartext vor.
- Der Server antwortet mit einer 401-Unauthorized-Antwort. Darin übermittelt er eine nonce, eine zufällige Zahl, die nur einmal verwendet wird.
- Der Client ermittelt einen Hashwert (MD5) aus Benutzer, nonce und Passwort.
- Der Server prüft, ob das Passwort zu dem hinterlegten passt.
Web Caching
Erweiterung durch HTTP 1.1.Durch die Zwischenspeicherung fragt der Browser nur noch nach geänderten Inhalten. Das Ziel ist es, teure Anfragen über das Netzwerk zu reduzieren oder sogar zu vermeiden.
- Validation: Die Seite besitzt einen "Last modified"-Header. Der Server wird befragt, ob er eine neuere Version hat.
- Invalidation: Wurde ein PUT, POST oder DELETE auf die Webseite angewendet, wird der Cache verworfen.
Der Server antwortet mit 304 Not Modified ohne die Seite, da diese dem Client ja vorliegt oder mit einer normalen 200 OK-Antwort mit der Seite, wenn die vorliegende Seite neuer ist.
Eine Webseite wurde von einem Server geladen und in den Cache eingelagert.
Zur sinnvollen Verwendung von Caches ist es hilfreich, wenn die Webseite in ihrem HTML-Code ein Entstehungsdatum enthält:
<meta name="date" content="2024-02-15">
HTTP/1.1 200 OK Content-Type: text/html Content-Length: 1024 Date: Tue, 22 Feb 2022 22:22:22 GMT Last-Modified: Tue, 22 Feb 2021 22:22:22 GMTDieselbe Seite soll wieder angefordert werden.
GET /index.html HTTP/1.1 Host: example.com Accept: text/html If-Modified-Since: Tue, 22 Feb 2021 22:22:22 GMTGibt es eine neuere Seite, sendet der Server diese. Ansonsten 304:
HTTP/1.0 304 Not Modified
Cookies
HTTP ist eigentlich statuslos. Das bedeutet, dass eine Anfrage nicht mehr weiß, was in der vorigen Anfrage geschehen ist. Für verlinkte Dokumente ist das ausreichend, aber bei einem Shop will der Benutzer seinen Einkaufswagen behalten, wenn er auf die nächste Seite wechselt.Cookies sind kleine Dateien, die der Server beim Eröffnen der Shopping-Tour an den Client (Browser) im Header-Feld set-cookie sendet.
Der Cookie enthält die URL der austeilenden Webseite. Sobald der Browser diese URL oder eine URL ein weiteres Mal aufruft, wird er den Cookie mitsenden.
Der Cookie enthält für die URL eine eindeutige Sitzungsnummer oder Kennung in Form einer Zuweisung, die es der Webseite ermöglicht, den Kunden und seinen Einkauf eindeutig zu identifizieren. Weitere Informationen können sein:
- Expires
- Domain
- Max-Age
- Path
- Secure: Nur bei HTTPS-Verbindung senden
- Version
Probleme ergeben sich, wenn Cookies an Server weitergegeben werden, die gar nicht der Shop-URL entsprechen, weil dieser Server dann nachvollziehen kann, welchen Shop der Client besucht hat. Das kann dadurch erfolgen, dass beispielsweise über Like-Buttons oder Werbung andere URLs beim Bezug einer Seite geladen werden. Der Betreiber der anderen URL kann aber in der Regel anhand der vergebenen Werbe-ID feststellen, von welcher Website die Werbung bzw. der Like-Button bereitgestellt wird. Auf diese Weise lässt sich von diesem die Spur des Anwenders über mehrere Webseiten verfolgen.